a 11 de Octubre, 2016
Introducción
Esta claro que el mundo de fútbol levanta pasiones, el fútbol y todo lo que lo rodeada, entre ellas algunas web que nos permiten gestionar de manera virtual a nuestro equipo, además de recoger los puntos de la jornada sirve para confeccionar el once inicial.
En este caso, nuestro objetivo es poder llegar a segmentar a los jugadores de la liga profesional de fútbol en función a una serie de inputs que la web pone a nuestra disposición, y de esta forma poder ayudar en la toma decisiones a la hora de gestionar mi equipo. http://www.comuniazo.com/

Análisis
En primer lugar necesitamos extraer la información necesaria para seleccionar los atributos que determinaran la segmentación. Para ello, realizamos scraping a la web «comuniazo» a través de la siguiente url:
url <- "http://www.comuniazo.com/comunio/jugadores"
La libreria XML nos permite extraer información de la página web mediante la función readHTMLTable
library(XML)
jugadores= readHTMLTable(jugadores,
stringsAsFactors = T,
colnames = c("Posicion","Equipo","Jugador","Puntos","Media","Puntos_Casa","Media_Casa","Puntos_Fuera","Media_fuera", "Valor"),
colClasses = c("character","character","character","FormattedNumber","FormattedNumber","FormattedNumber","FormattedNumber","FormattedNumber","FormattedNumber"))
El dataset esta formado por 504 registros y 14 variables candidatas.
Análisis de componentes principales
A continuación vamos a aplicar una de las técnicas de reducción de dimensionalidad , aplicamos análisis de componentes principales de los datos en R, para ello previamente escalaremos el dataset:
# Seleccionamos los atributos numéricos y escalamos jugadores_num <- jugadores[,4:10] jugadores_scale <- scale(jugadores_num) # Aplicamos análisis de componentes principales pc <- princomp(jugadores_scale) plot(pc) plot(pc, type = "l") summary(pc)
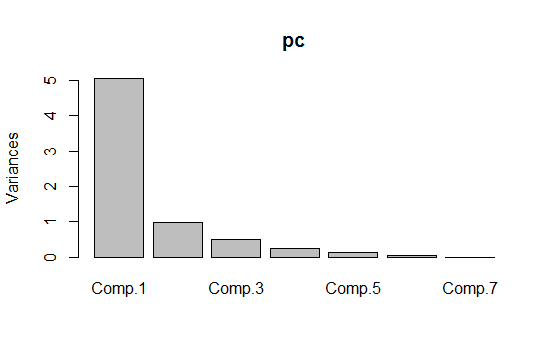
 Seleccionando dos componentes principales conseguimos explicar el 86% de la varianza.
Seleccionando dos componentes principales conseguimos explicar el 86% de la varianza.
# Obtenemos componentes principales pc <- prcomp(jugadores_scale) summary(pc) Importance of components: Comp.1 Comp.2 Comp.3 Comp.4 Standard deviation 2.2477665 0.9923867 0.71057691 0.50588385 Proportion of Variance 0.7232142 0.1409699 0.07227477 0.03663246 Cumulative Proportion 0.7232142 0.8641840 0.93645881 0.97309127 Comp.5 Comp.6 Comp.7 Standard deviation 0.37326927 0.22058428 0 Proportion of Variance 0.01994385 0.00696488 0 Cumulative Proportion 0.99303512 1.00000000 1 # Primeras componentes principales comp <- data.frame(pc$x[,1:2])
Análisis Cluster
Vamos a segmentar con la técnica más simple, para ello utilizaremos k-medias en R.
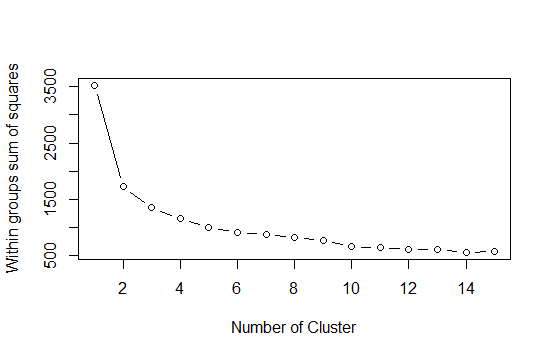
En primer lugar, ¿cómo determinamos el número de grupos? El método más simple es mirar a la suma de cuadrados dentro de los grupos y escoger el «punto» en la gráfica, de forma similar a como ocurre con el gráfico de sedimentación que hicimos para el PCA previamente. A continuación mostramos el código utilizado:
# Plot plot(comp, pch = 16, col= rgb(0,0,0,0.5)) wss <- (nrow(jugadores_scale)-1)*sum(apply(jugadores_scale,2,var)) for (i in 2:15) wss[i] <- sum(kmeans(jugadores_scale, centers =i)$withinss) plot(1:15, wss, type = "b", xlab = "Number of Cluster", ylab = "Within groups sum of squares")
# K-Means Clustering con 6 clusters jugadores_Cluster <- kmeans(comp, 6, nstart = 25, iter.max = 1000) jugadores_Cluster aggregate(jugadores[,4:10], by=list(jugadores_Cluster$cluster), FUN = mean) K-means clustering with 6 clusters of sizes 72, 114, 71, 64, 144, 39 Cluster means: PC1 PC2 1 -1.51933814 -1.1588460 2 0.81871056 -0.4593748 3 -0.09203462 0.9141368 4 -2.37569832 0.9286046 5 2.47658186 0.1106443 6 -4.66639217 -0.1143984 Clustering vector: [1] 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 4 6 6 6 6 6 6 6 6 4 6 4 6 6 6 6 6 [34] 6 6 4 4 6 6 1 4 4 6 6 6 4 1 4 1 4 4 4 1 4 1 4 4 1 4 4 4 1 4 4 6 1 [67] 4 1 4 1 1 1 4 4 4 4 4 4 4 1 6 1 4 4 4 1 1 4 4 4 1 4 4 4 4 1 4 4 4 [100] 1 4 4 4 4 1 4 4 1 4 1 4 4 1 1 4 4 1 1 4 1 1 1 1 1 1 4 4 1 1 4 4 1 [133] 4 3 3 3 1 3 1 1 3 3 1 3 1 4 1 1 1 3 1 1 1 3 1 4 3 3 1 1 3 3 1 1 1 [166] 1 2 1 3 3 2 1 3 3 1 3 1 3 3 1 3 1 1 1 1 3 3 3 2 3 2 3 3 2 4 1 1 3 [199] 1 2 3 3 1 2 1 2 2 3 2 3 3 3 2 2 2 2 3 3 2 1 1 3 2 3 3 3 3 3 4 4 3 [232] 1 2 2 2 3 3 2 2 3 3 2 2 2 3 2 2 2 2 1 3 3 2 2 3 3 2 2 2 2 2 3 2 2 [265] 2 3 2 3 2 2 2 2 2 2 2 2 2 2 2 3 3 2 3 2 2 2 2 2 2 2 2 2 2 3 2 2 2 [298] 3 3 3 2 2 2 2 2 3 3 3 3 2 1 3 2 2 2 2 2 2 2 2 5 2 2 3 5 2 2 2 3 2 [331] 3 2 2 2 2 2 2 2 2 2 2 2 2 2 2 5 2 5 5 2 2 5 3 5 2 2 2 2 5 5 5 5 2 [364] 5 2 2 2 2 2 5 2 5 2 2 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 [397] 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 [430] 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 [463] 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 [496] 5 5 5 5 5 5 5 5 5 Within cluster sum of squares by cluster: [1] 76.21358 75.80518 55.22837 67.37217 75.01832 118.73351 (between_SS / total_SS = 84.6 %) Available components: [1] "cluster" "centers" "totss" "withinss" [5] "tot.withinss" "betweenss" "size" "iter" [9] "ifault"
Una vez calculados los clusters correspondientes los visualizaremos en función de las dos componentes principales utilizadas:
library(ggplot2) jugadores$cluster <- as.factor(jugadores_Cluster$cluster) jugadores$PC1 <- comp$PC1 jugadores$PC2 <- comp$PC2 ggplot(jugadores, aes(PC1, PC2, color = jugadores$cluster)) + geom_point()

El siguiente paso sería identificar los segmentos y establecer una etiqueta que los identifique y poder gestionar la estrategia.
Hasta aquí llega este post. ¡Espero que le haya gustado! Cualquier pregunta o comentario, no dude en dejar un comentario o acercarse a mí en Twitter: @mirallesjm

Enhorabuena José Miguel!!!,
buen acercamiento de las técnicas de ML al mundo del fútbol.
Un comentario…..Nasri en el cluster TOP? jajajajajaja
Me gustaMe gusta